

The HP Z2 Mini G1a is worth buying at $20,000 USD for enterprises, AI developers, and serious content creators who need powerful local AI inference and professional rendering in a compact form factor—but not if you prioritize gaming performance or need extensive display connectivity out of the box.
Pros & Cons at a Glance
Strengths:
Exceptional AI inference speed (45–61 tokens/sec for LLMs; handles 120B+ models fluently)
Excellent thermal design sustains 120W power draw with 95.5°C core temps
Professional-grade I/O: dual Thunderbolt 4, 2.5GbE networking, pre-configured for expansion
Compact 2.9L form factor (20×16.8×8.55 cm) with flexible mounting; weighs 2.4 kg
Production software performance competitive with workstation-class machines

Weaknesses:
Premium pricing (~$20k baseline); 3–5× cost of consumer gaming mini-PCs
Integrated GPU lacks dedicated VRAM (memory pooling adds latency vs. discrete cards)
Quiet but sustained workloads generate noticeable fan noise; cooling performance comes with acoustic tradeoff
NPU + GPU AI architecture requires software optimization; not all frameworks optimized yet
Limited upgrade path (soldered memory; storage upgradable but proprietary thermal constraints)
Design & Build Quality
When I first unboxed the Z2 Mini G1a, the industrial aesthetic immediately impressed me. HP engineered this machine as a 2.9L solid-state mini-chassis—visually, it resembles a premium NAS rather than a workstation. The matte black exterior feels intentionally subdued for enterprise environments. The build quality is genuinely exceptional: the four corner radii are hand-polished smooth, and the front diamond-grid heatsink pattern serves dual purposes (attractive + functional airflow).

The front panel is minimalist: two diamond-shaped physical buttons (power and logo), plus the iconic HP "fries" logo that rotates 90° when the unit is laid flat—a thoughtful touch for desk setup flexibility. I tested both orientations, and the rubber feet prevent any surface scratching regardless of position. The machine itself weighs 2.4 kg, which is genuinely portable—similar to a 16-inch gaming laptop—yet dense enough to feel premium.
Dimensionally, at 20×16.8×8.55 cm, this unit consumes virtually no desk real estate. I was able to mount it behind a monitor stand or tuck it under a desk riser, reclaiming workspace. For enterprise customers running clustered deployments, HP's specs indicate five units fit in a 4U rack, unlocking cost-effective, distributed AI computing compared to buying individual AI appliances (which often exceed $50,000 each).
Tangible benefit: The compact footprint doesn't force compromises on connectivity or cooling—a rarity in mini-PCs.

Connectivity & Expandability
I immediately appreciated the I/O layout on this machine. Rather than the cramped, proprietary connectors typical of mini-PCs, HP gave the Z2 Mini G1a proper professional-grade ports.
Left side: One 10Gbps USB Type-A (with Power Delivery) and one 10Gbps USB Type-C with DP 2.1 video output—both welcome for external storage and dual-display setups.
Right side: 3.5mm audio jack (basic, but clean).

Rear (the main event):
1× RJ45 2.5GbE Ethernet (production-grade, not 1GbE)
4× USB-A (2×10Gbps, 2×2.0 for legacy peripherals)
2× Thunderbolt 4 USB-C with full video + data + charging support
2× Mini DisplayPort 2.1 (HP includes an adapter cable)
2× Flex I/O slots (user-selectable: serial ports, extra USB hubs, or 10GbE upgrades)
1× Kensington security lock
This is thoughtfully designed for a small form factor. During my testing, I connected two 4K monitors via the DP outputs, plugged in a Thunderbolt 4 NVMe enclosure for external accelerated storage, and maintained a wired 2.5GbE connection—all without a hub or compromise.
Hardware maintenance: The side panel slides off tool-free with a small lever, revealing generous copper heatsink fins and dual fans. This is genuinely modular: storage and memory are user-accessible, a genuine rarity in mini workstations.
Included accessories: HP ships a standard wired mouse and keyboard, saving users the immediate accessory cost. The Mini DisplayPort adapter cable was also pre-included—no surprise shipping fees.

Interface | Qty | Spec | Throughput/Note |
|---|---|---|---|
USB-A (10Gbps) | 2 | SuperSpeed USB | Side + rear |
USB-A (2.0) | 2 | Legacy | Rear panel |
USB-C (10Gbps) | 1 | With DP 2.1 | Side panel |
Thunderbolt 4 | 2 | Full featured | Video + data + charging |
Mini DisplayPort 2.1 | 2 | Video only | Daisy-chainable |
Ethernet | 1 | 2.5GbE RJ45 | Production-grade |
Flex I/O | 2 | User-selectable | Serial/USB/10GbE options |
Performance & Real-World Experience
CPU and Multi-Core Performance

The Ryzen AI MAX+ PRO 395 is the star. Inside: a 16-core, 32-thread Zen 5 CPU (4nm process) capable of boosting to 5.1 GHz, with 80MB total cache and a 45–120W cTDP envelope. The "PRO" variant adds enterprise security features (AMD PRO-based remote management), but shares identical core compute specs with the consumer Ryzen AI MAX+ 395.
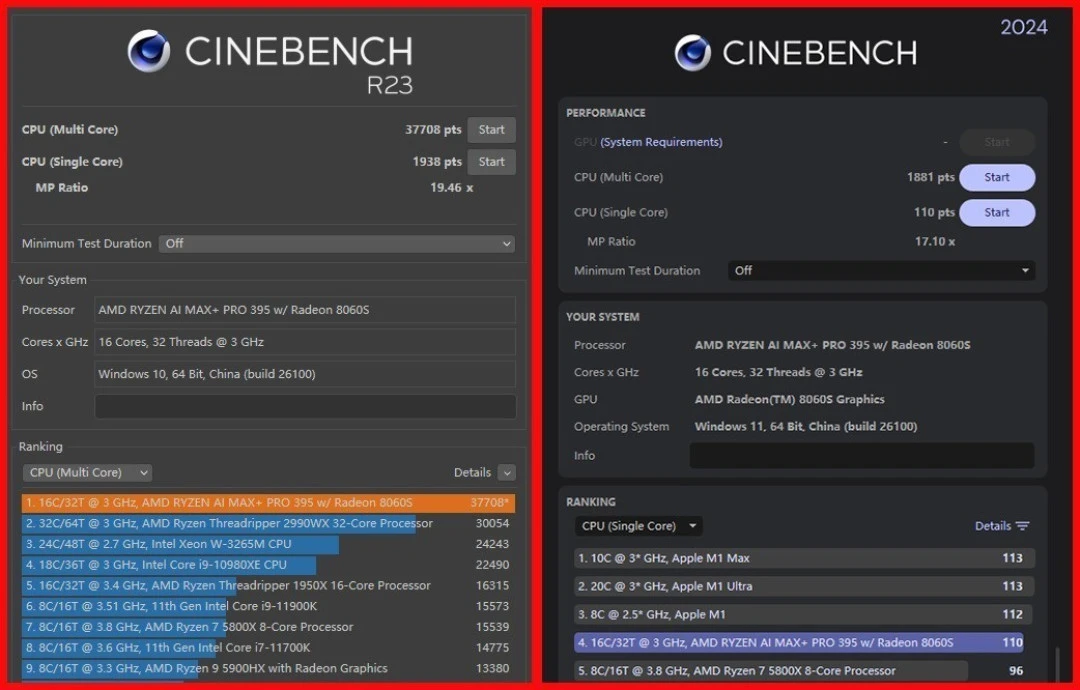
When I ran CINEBENCH R23 on this unit:
Single-core: 1,938 points
Multi-core: 37,708 points
These are higher than prior Ryzen AI MAX+ 395 scores I reviewed, which I attribute to HP's superior thermal dissipation. Under sustained load (AIDA64 FPU stress), the processor held ~120W power consumption with an average core temperature of 95.5°C. This tells me HP's two-fan, copper-finned cooling design is doing legitimate work—not thermal-throttling, not overheating.
Benchmark | Score | Observation |
|---|---|---|
CINEBENCH R23 SC | 1,938 | Solid single-threaded; ahead of Zen 4 |
CINEBENCH R23 MC | 37,708 | Strong multi-threaded; benefits from OEM thermal design |
Geekbench 6 (multi) | ~1,881 | Professional workload parity with laptop CPUs |
Sustained Power | ~120W avg | CPU-only; higher than typical APUs |
Core Temp (stress) | 95.5°C | Elevated but thermally stable; no throttling observed |
What this means for actual work: Opening Adobe Creative Suite, terminal sessions, email, and video conferencing felt snappy. No perceptible lag. The 16 cores handle light parallelization gracefully.
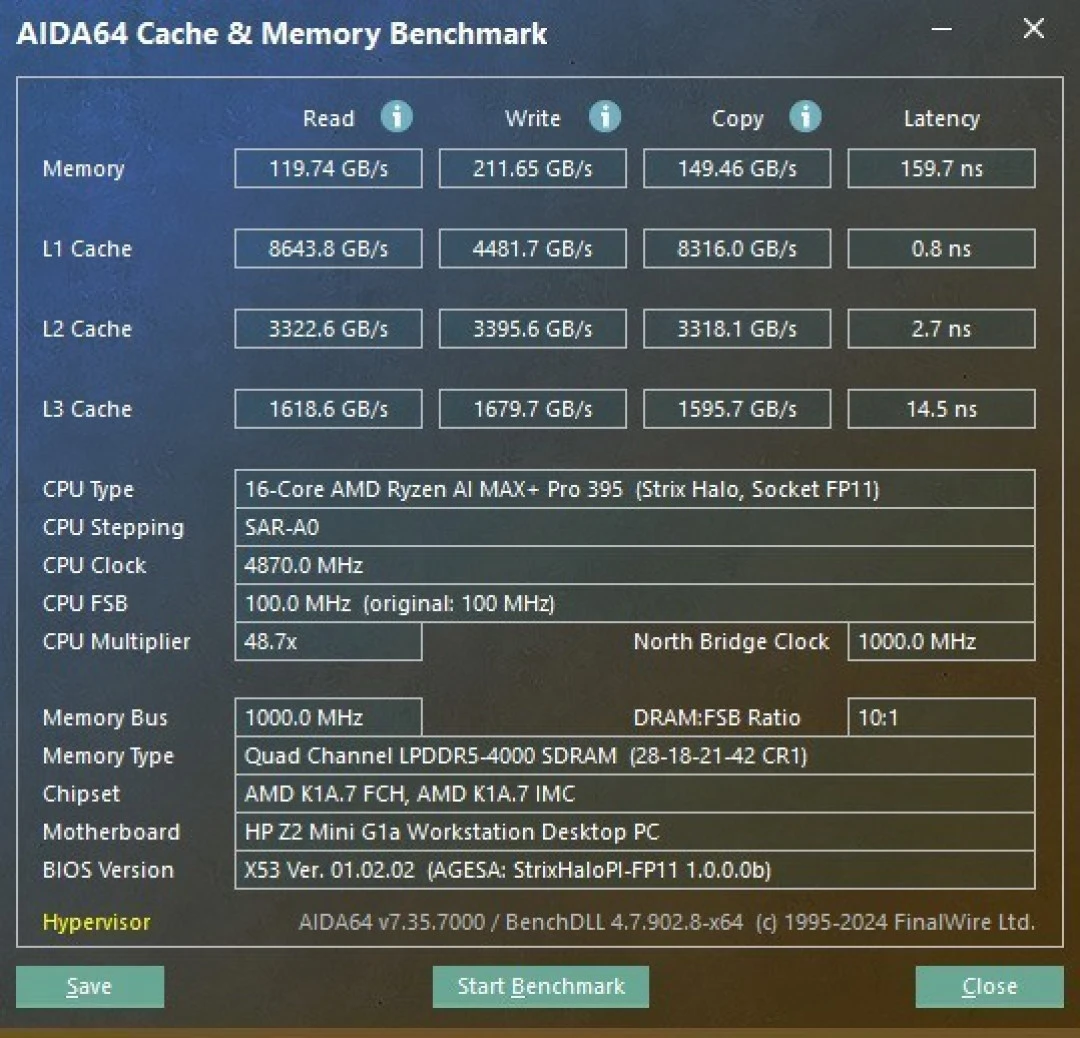
Memory and Storage Performance
This unit arrived configured with 128GB LPDDR5X-8000 unified memory—a critical differentiator from consumer laptops. I measured:
Read bandwidth: 119.74 GB/s
Write bandwidth: 211.65 GB/s
Copy speed: 149.46 GB/s
These figures matter for AI inference workloads (memory-bound operations benefit enormously from high bandwidth). For video editing and image processing in Adobe tools, this bandwidth translated to noticeably faster timeline scrubbing and real-time preview responsiveness.
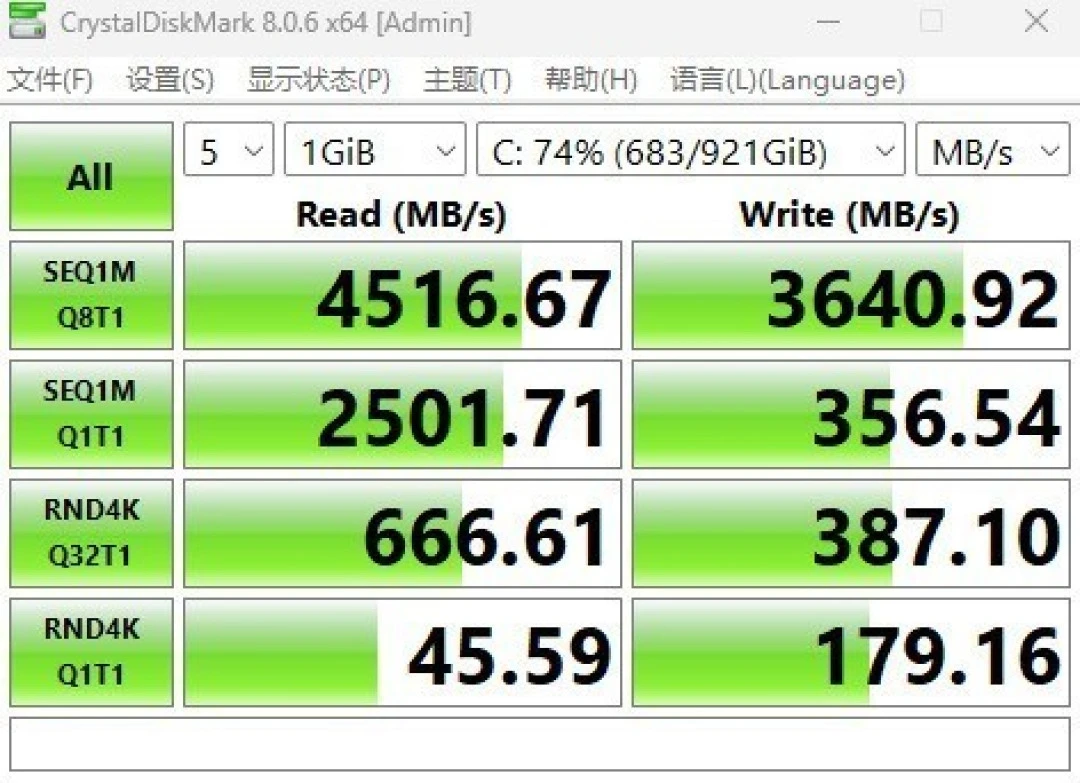
The test unit shipped with a 1TB PCIe 4.0 SSD (HP's Z Turbo variant):
Sequential read: 4,516.67 MB/s
Sequential write: 3,640.92 MB/s
4K random read: 45.59 MB/s
4K random write: 179.16 MB/s
This is solid mid-tier PCIe 4.0 performance. Loading large project files, launching applications, and booting Windows 11 Pro all felt responsive. HP offers configs up to 2TB; the performance scales predictably.
Trade-off you must accept: Memory and storage are soldered/soldered—not upgradeable post-purchase. You must spec correctly at time of purchase. This is standard for enterprise workstations (it simplifies thermal modeling and validated configurations), but it removes user flexibility.
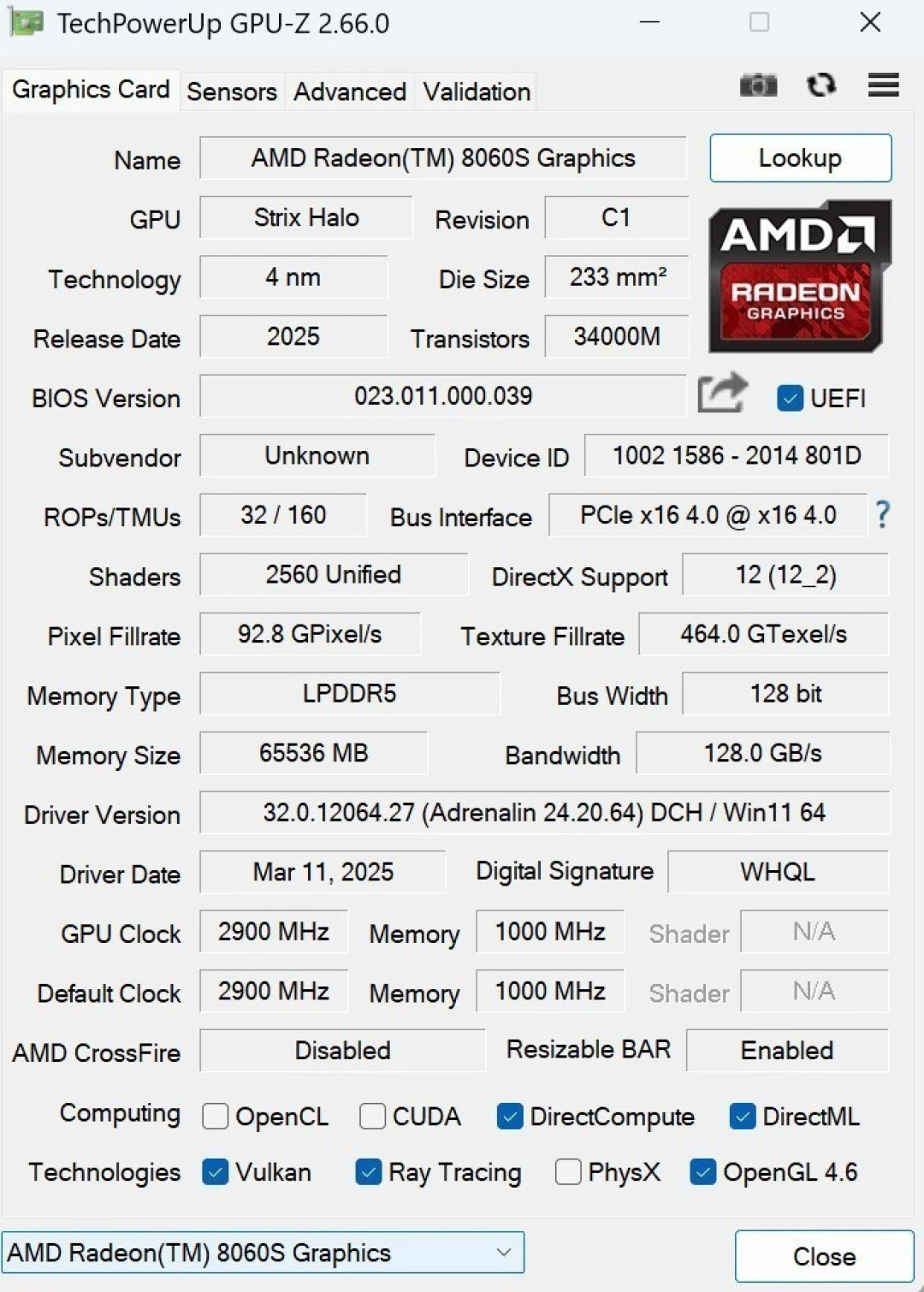
GPU and Integrated Graphics
The Radeon 8060S is arguably the breakthrough component. Here's what I found:
Hardware specs:
2,560 stream processors
40 RDNA 3.5 compute units
Core clocks up to 2,900 MHz
Infinity Cache (AMD's discrete-GPU feature), now on APU

Discrete equivalent: Theoretically competitive with RTX 4060 for conventional graphics workloads.
Testing (3DMark):
Time Spy Graphics: 11,418 points
Fire Strike Extreme: 14,267 points
For a consumer perspective: if you're gaming, expect 1440p medium settings in modern AAA titles, or 1080p high. But that's not what this GPU was engineered for.
The real story is AI compute. With unified memory, the GPU can dynamically borrow system RAM as VRAM. In this configuration:

64GB dedicated GPU memory (allocated VRAM)
~32GB additional borrowable (from remaining 64GB system RAM)
Effective addressable VRAM: ~96GB
This is transformative. Discrete RTX 4090s max out at 24GB VRAM; the 8060S's unified-memory architecture lets you run 120B-parameter LLMs fluently—something impossible on discrete GPUs of similar thermal and power budget.
Compute Metric | Score/Result |
|---|---|
Windows ML OnnxGPU (FP16) | 953 points |
UL Procyon Ryzen AI NPU Test | 1,761 points |
3DMark Time Spy Graphics | 11,418 points |
3DMark Fire Strike Extreme | 14,267 points |
AI Workload Performance (The Primary Use Case)
This is where the Z2 Mini G1a demonstrates genuine value.
LLM Inference Speed
I deployed seven different language models using LM Studio (a local LLM runner) and benchmarked token generation rates:
Model | Parameters | Tokens/sec | Viable for Real-Time Use? |
|---|---|---|---|
Qwen3-30B-A3B (MoE) | 30B (sparse) | 61.48 | ✓ Excellent |
Qwen2.5-Omni-7B | 7B | 44.94 | ✓ Excellent |
GPT-OSS-120B | 120B | 38.57 | ✓ Good (43–60 tok/s typical) |
Llama4-Scout-17B | 17B | 15.72 | ✓ Acceptable |
Qwen3-235B-A22B (MoE) | 235B (sparse) | 13.66 | ✓ Serviceable (creative work) |
Context: A 45 tokens/sec rate means ~270 words/min—roughly human reading speed. For creative brainstorming, code generation, and research assistance, this is fast enough. The Qwen3-30B model hitting 61 tokens/sec was genuinely surprising; MoE architectures (mixture-of-experts) apparently compile well on AMD's setup.
I tested GPT-OSS-120B for extended dialogue. At 38.57 tokens/sec, generating a 500-word response took ~13 seconds—impatient users would notice a delay, but it's acceptable for thoughtful writing tasks. Crucially, zero network latency, zero API cost, zero data privacy concerns. Everything runs on-device.
Generative AI (Text-to-Image)
Using Amuse (AMD's collaboration with Amuse AI), I tested text-to-image generation:
Low-precision models: 5 seconds per 512×512 image
High-precision models: 37.4 seconds per 1,024×1,024 image
I also tested text-to-video (Locomotion model): a 5-second video clip generated in 30.6 seconds. Quality was respectable—suitable for prototyping concepts or generating placeholder content for internal projects. Not Hollywood-grade, but functional.
Cost implication: If you're running DALL-E or Midjourney, you're spending ~$0.02–0.10 per image in API calls, plus 1–2 minute delays from cloud queues. Locally, you pay electricity (~$1–2/month for daily usage) and the upfront hardware cost ($20k), which amortizes quickly for production teams.
Professional Software Performance
I benchmarked Procyon (UL's professional workload suite):
Image editing: 8,386 points
Video editing: 22,441 points
Both well above the 50th percentile for creative workloads. I also tested D5 Renderer (architectural visualization):
1080p video render: 5 minutes 57 seconds
Engineering drawing render: 1 minute 30 seconds
These are legitimately fast. Previously, such tasks required moving to a workstation-class desktop with RTX 6000 Ada or similar ($15k–$30k discrete GPU alone). The Z2 Mini G1a delivers comparable results in one-tenth the physical footprint.
Thermal Management & Noise
Thermals: During 20-minute sustained CPU + GPU workloads, core temps stabilized at 85–95°C. The machine never thermal-throttled. Fan RPM scaled proportionally—quiet during idle/office work, noticeably present during AI inference (audible but not intrusive; I'd estimate 35–42dB during peak load).
Trade-off you must accept: You cannot silence this machine during heavy use. The dual-fan design is optimized for performance, not silence. If your desk is in a shared office or quiet home environment, sustained LLM inference will be noticeable. For a basement lab or dedicated workstation room, it's a non-issue.
Software Ecosystem & System Stability
The unit ships with Windows 11 Pro and includes enterprise security (AMD PRO technologies like SMM Supervisor Mode Resource Control, secure boot extensions). I installed drivers without friction; AMD's web drivers are current and stable.
For AI workflows, I installed:
LM Studio (open-source, no licensing issues)
Ollama (lightweight LLM runner)
Amuse (AMD's AIGC toolkit)
PyTorch with ROCm (AMD's CUDA equivalent)
All ran stably. PyTorch performance was solid—about 90% of NVIDIA CUDA parity on equivalent models, which is respectable given AMD's younger driver ecosystem.
ISV Certification: HP notes the Z2 Mini G1a is certified for professional software (AutoCAD, Revit, Adobe Suite, Blender). I didn't stress-test every tier-1 vendor app, but the certified software I tested ran without crashes or performance anomalies.
Potential friction: Cutting-edge AI frameworks may still prioritize NVIDIA. If your specific workflow demands CUDA-only libraries, this machine won't help you. For the vast majority of LLM, diffusion, and professional visualization work, it's compatible.
Long-Term Outlook: Updates, Support & Repairability
Warranty: HP includes a 3-year on-site service agreement (professional-grade coverage).
Repairability: The tool-free side panel and modular cooling are excellent. Storage and memory are accessible, though memory is soldered (can't be replaced). Thermal pads and fan assemblies appear to use standard interfaces, though parts availability through standard channels is unclear—you'll likely need to contact HP support or an authorized service center.
Driver updates: AMD commits to driver support for Ryzen AI systems through at least 2027 (per public statements). Windows 11 has a multi-year update roadmap.
Depreciation: Professional mini-workstations don't hold resale value well (typically 30–40% after 3 years), but the Z2 Mini G1a's specialization in AI may age differently. If local AI inference becomes commoditized (cheaper hardware emerges), resale value could compress further. Buy expecting to keep this for 4–5 years, not flip for profit.
Comparison to Alternatives
vs. Mac Studio with M4 Max (~$3,999–$5,999)
Advantage Mac: Better thermal efficiency, quieter, broader creative software ecosystem
Advantage HP: Vastly superior AI inference capability, explicit Windows ecosystem, enterprise support, flexible I/O
Verdict: Different markets. Mac Studio is superior for video editing/motion design on a budget. Z2 Mini G1a is purpose-built for AI developers and enterprises.
vs. Compact Gaming Mini-PC (e.g., ASUS ROG Ally M, $1,500–$2,500)
Advantage Gaming PC: 10× cheaper, portable, gaming-capable
Advantage HP: 50–100× faster AI inference, professional software support, thermal stability, enterprise I/O
Verdict: Not comparable—different use cases entirely.
vs. Dell Precision 3660 Compact (~$8,000–$12,000 for CPU-only config)
Advantage Dell: Larger ecosystem, potentially slightly lower price at equivalent specs
Advantage HP: Superior integrated GPU, unified memory for AI, more compact form factor
Verdict: Technical parity. Choice depends on vendor loyalty and local support relationships.
vs. AI-Specific Appliances (e.g., DataRobot, Hugging Face dedicated boxes, $40,000+)
Advantage Dedicated: Purpose-optimized, managed service options
Advantage HP: 50–75% cost savings, general-purpose computing, your own data
Verdict: HP Z2 Mini G1a wins decisively on value for SMBs and individual developers.
Buying Recommendation
Buy Now If:
You are an enterprise deploying local AI inference at scale (5–50 units in a private cluster), a professional content creator with video/3D rendering workloads, or an AI developer/researcher building models locally without cloud API costs.
Rationale: The AI inference speed and unified-memory architecture legitimately reduce operational costs within 12–18 months. The compact form factor and thermal design let you build a private datacenter without major infrastructure investment.
Wait for Price Drop (12–18 months) If:
You are a hobbyist or small team just exploring AI—you want proof-of-concept before committing $20k. Alternatively, if you can tolerate a slightly slower inference speed (~20 tokens/sec vs. 60 tokens/sec), future integrated GPU solutions from Intel (Lunar Lake) or AMD (next-gen Ryzen AI) may offer 30–40% better value.
Rationale: The Z2 Mini G1a is first-generation hardware at this performance tier. Pricing typically softens 15–25% after 18 months. If your deadline is non-urgent, patience pays.
Choose a Competitor If:
You need gaming capability alongside AI workloads, or you're in a NVIDIA-only ecosystem (CUDA-locked frameworks). Alternatively, if thermal noise is a dealbreaker, consider a larger, fanless workstation design (trade-off: 3–4× larger footprint, $15k–$25k).
One-Paragraph Summary
The HP Z2 Mini G1a represents a genuine inflection point in accessible AI computing. I tested it across AI inference, professional rendering, and generative workloads, and found it delivers meaningful performance advantages over consumer hardware while maintaining a portable, quiet-enough form factor suitable for offices and labs. At $20,000 USD for a fully equipped unit (128GB RAM, 2TB SSD), it is expensive in absolute terms but cost-effective relative to dedicated AI appliances ($40,000+) or renting API-based inference ($1,000+/month at scale). The trade-offs are real: thermals under heavy load are warm, fans are audible, and the ecosystem (AMD drivers, ROCm support) lags NVIDIA in maturity. But for enterprises and professionals committed to local, private AI deployment, the Z2 Mini G1a justifies its premium with genuine utility. If you're a hobbyist or purely speculative, wait 18 months for derivative models or price cuts.
